I have previously performed a benchmark on a variety of web servers in 2012 and have had some people request that I redo the tests with newer versions of the web servers as no doubt a lot has likely changed since then.
Here I’ll be performing benchmarks against the current latest versions of a number of Linux based web servers and then comparing them against each other to get an idea of which one performs the best under a static workload.
First I’ll discuss how the tests were set up and actually done before proceeding into the results.
The Benchmarking Software
Once again I made use of Weighttpd to perform the actual benchmark tests, as I’ve found that it works well and scales quite nicely with multiple threads.
This time around I ran weighttpd on its own virtual machine, I did not do this previously as I wanted to avoid the network stack to get the absolute best performance possible. The problem with running weighttpd on the same server that is running the web server software, is that a significant amount of CPU resources end up being used by the test itself which are thereby taken away from the web server.
Again weighttpd was run via the ab.c script, which essentially automates the testing process for me. Instead of running hundreds of weighttpd commands I use this script to step through different concurrency levels automatically.
weighttp -n 100000 -c [0-1000 step:10 rounds:3] -t 8 -k "http://x.x.x.x:80/index.html"
Where -n is the number of requests, in this case we are sending 100,000 requests for every concurrency level of -c specified. Thanks to ab.c, we are able to step through from 0 simultaneous requests up to 1,000 in increments of 10 at a time. Each test is also performed 3 times as specified in the rounds, this way I am able to get a better average result as each concurrency level is run 3 times. In total every test therefore results in around 30,000,000 GET requests being sent to the web server at http://x.x.x.x:80/index.html.
The -t flag specifies the amount of threads to use, this was adjusted from 1, 2, 4 and 8 depending on the amount of CPU cores assigned to the web server for each test. The -k flag is also specified as we are making use of keep alive.
The Test Environment
In order to perform the tests I made use of two virtual machines that were running on top of VMware ESXi 5.5, so while an extremely small amount of additional performance could have been gained from running on bare metal, making use of virtual machines allowed me to easily modify the amount of CPU cores available when changing between the tests. I’m not trying to get the absolute best performance anyway, as long as each test is comparable to the others then it’s fine and I can adequately test what I am after.
The physical server itself that was running ESXi had two CPU sockets, each with an Intel Xeon L5639 CPU @ 2.13GHz (Turbo 2.7GHz), for a total of 12 CPU cores. This is completely different hardware than what I used for my tests in 2012, so please do not directly compare the amount of requests per second against the old graphs. The numbers provided in this post should only be compared here within this post as everything was run on the same hardware here.
Both the VM running the weighttpd tests and the VM running the web server software were running CentOS 7.2 with Linux kernel 3.10.0-327.10.1.el7.x86_64 installed (fully up to date as of 05/03/2016). Both servers had 4GB of memory and 20gb of SSD based disk space available. The amount of CPU cores on the web server were adjusted to 1, 2, 4 and then 8.
The Web Server
While the web server VM had multiple different web server software installed at once, only one was actually running at any one time and bound to port 80 for the test. A system reboot was performed after each test as I wanted to get an accurate measure of the memory that was used from each test.
The web server versions tested are as follows, these are the latest most up to date versions currently available when the tests were performed 05/03/2016.
Update 1/04/2016: I have retested OpenLiteSpeed, as they made some fixes in response to this post in version 1.4.16.
Update 9/04/2016: I have retested Nginx Stable and Mainline versions, after some help from Valentin Bartenev from Nginx who reached out to me in the comments below I was able to resolve some strange performance issues I had at higher cpu core levels.
- Apache 2.4.6 (Prefork MPM)
- Nginx Stable 1.8.1
- Nginx Mainline 1.9.13
- Cherokee 1.2.104
- Lighttpd 1.4.39
- OpenLiteSpeed 1.4.16
- Varnish 4.1.1
It is important to note that these web servers were only serving a static workload, which was a 7 byte index.html page. The goal of this test was to get an idea of how the web servers performed with raw speed by serving out the same file. I would be interested in doing further testing in the future for dynamic content such as PHP, let me know if you’d be interested in seeing this.
While Varnish is used for caching rather than being a fully fledged web server itself, I thought it would still be interesting to include. Varnish cache was tested with an Nginx 1.8.1 back end – not that this really matters, as after the first request index.html will be pulled from the Varnish cache.
All web servers had keep alive enabled, with a keep alive timeout of 60 seconds, with 1024 requests allowed per keep alive connection. Where applicable, web server configuration files were modified to improve performance such as setting ‘server.max-worker’ in lighttpd to equal the amount of CPU cores as recommended in the documentation. Access logging was also disabled to prevent unnecessary disk I/O and to stop the disk from completely filling up with logs.
Server Configuration
The following adjustments were made to both the server performing the test and the web server to help maximize performance.
The /etc/sysctl.conf file was modified as below.
fs.file-max = 5000000 net.core.netdev_max_backlog = 400000 net.core.optmem_max = 10000000 net.core.rmem_default = 10000000 net.core.rmem_max = 10000000 net.core.somaxconn = 100000 net.core.wmem_default = 10000000 net.core.wmem_max = 10000000 net.ipv4.conf.all.rp_filter = 1 net.ipv4.conf.default.rp_filter = 1 net.ipv4.ip_local_port_range = 1024 65535 net.ipv4.tcp_congestion_control = bic net.ipv4.tcp_ecn = 0 net.ipv4.tcp_max_syn_backlog = 12000 net.ipv4.tcp_max_tw_buckets = 2000000 net.ipv4.tcp_mem = 30000000 30000000 30000000 net.ipv4.tcp_rmem = 30000000 30000000 30000000 net.ipv4.tcp_sack = 1 net.ipv4.tcp_syncookies = 0 net.ipv4.tcp_timestamps = 1 net.ipv4.tcp_wmem = 30000000 30000000 30000000 net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_tw_reuse = 1
The /etc/security/limits.conf file was modified as below.
* soft nofile 10000 * hard nofile 10000
These changes are required to prevent various limits being hit, such as running out of TCP ports or open files. It’s important to note that these values are likely not what you would want to use within a production environment, I am using them to get the best performance I can from my servers and to also prevent the test runs from failing.
Benchmark Results
Now that all of that has been explained, here are the results of my benchmark tests as graphs.
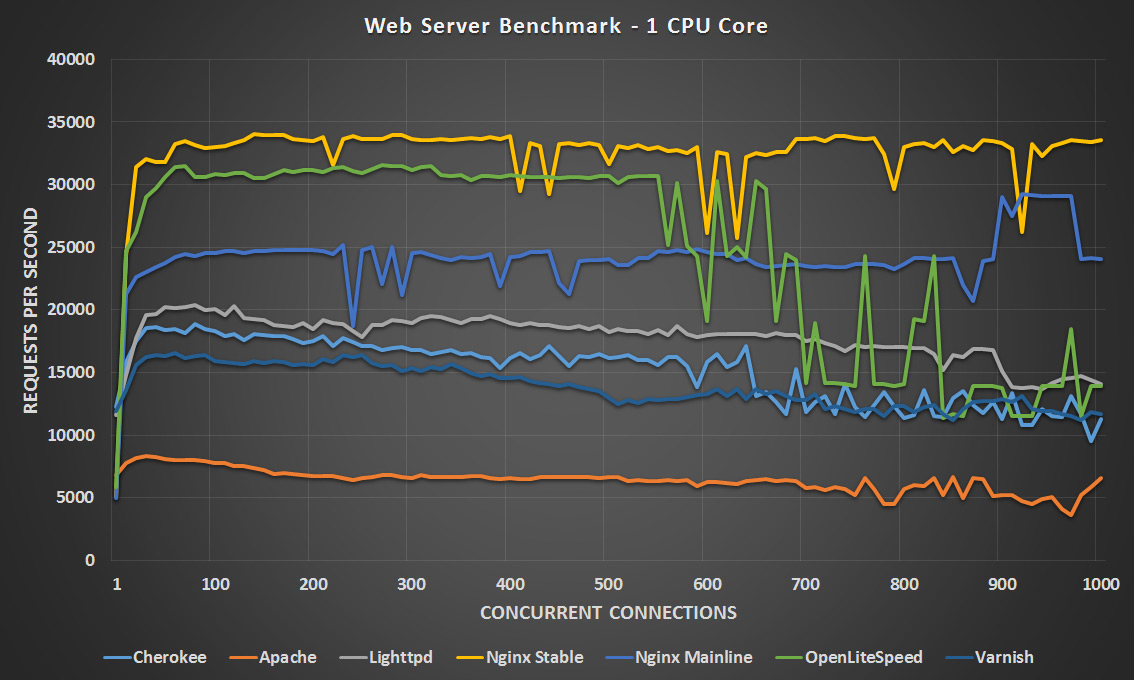
1 CPU Core – Click Image To Expand
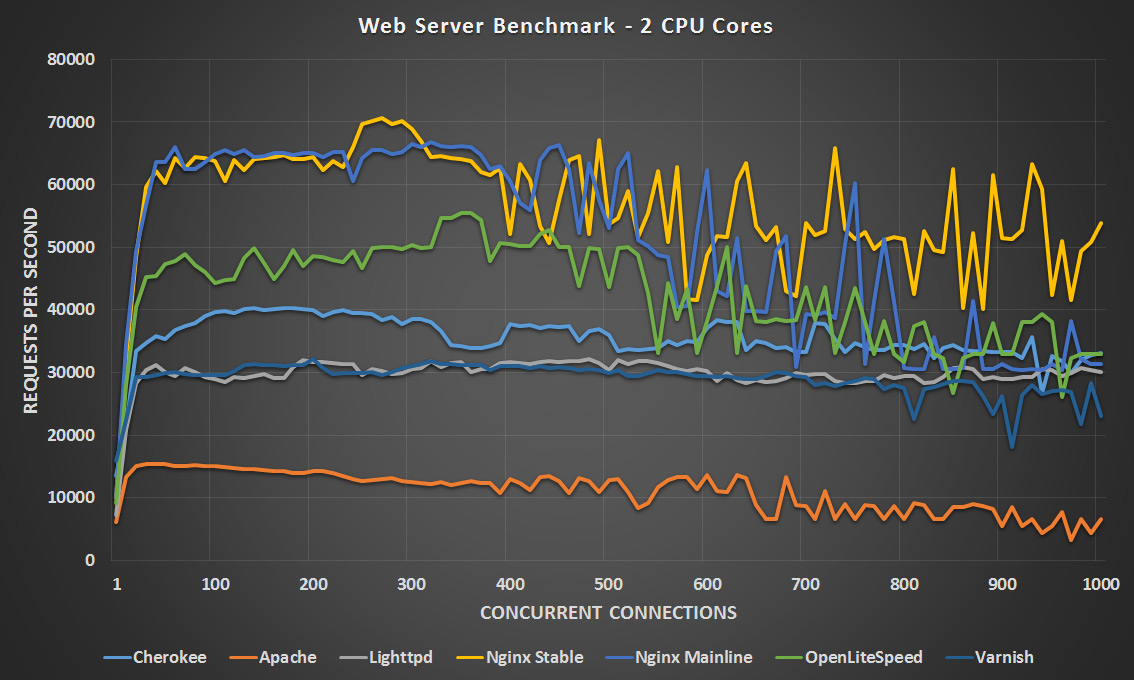
2 CPU Cores – Click Image To Expand
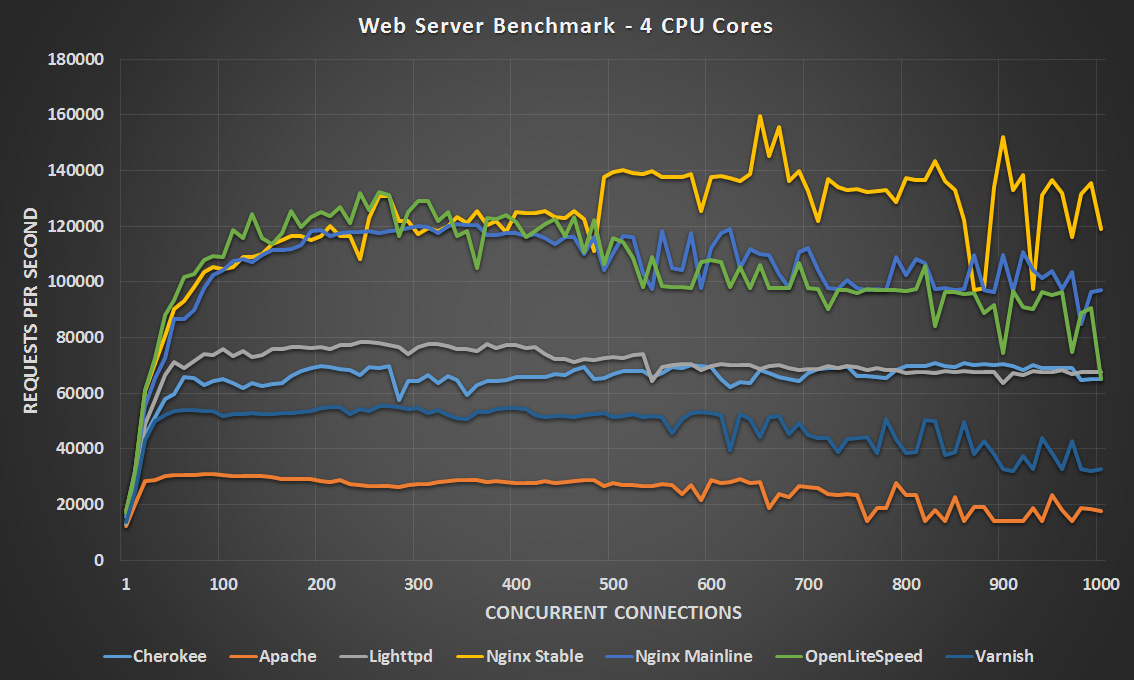
4 CPU Cores – Click Image To Expand
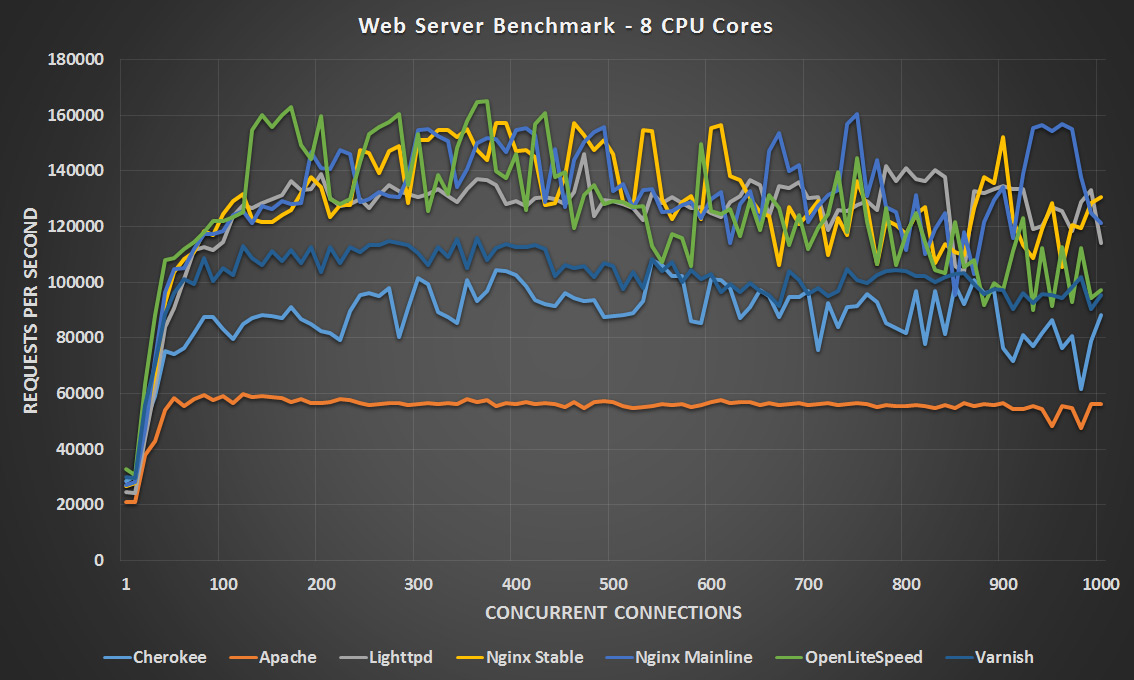
8 CPU Cores – Click Image To Expand
In general Apache still seems to perform the worst which was expected, as this has traditionally been the case. With 1 CPU core Nginx stable is clearly ahead, followed by OpenLiteSpeed until the 600 concurrency point where it starts to drop off and is surpassed by Nginx Mainline and Lighttpd at these higher concurrency levels. With two CPU cores Nginx mainline and stable are neck and neck however the stable version seems to perform better at the higher concurrency levels, with OpenLiteSpeed not too far behind and coming in third place.
With 4 CPU cores both versions of Nginx and OpenLiteSpeed are very close until the 500 concurrent connection point with OpenLiteSpeed slightly in the lead, however after 500 OpenLiteSpeed and Nginx Mainline drop off a little and appear to be closely matched while Nginx Stable takes the lead. At 8 CPU cores it’s a pretty tight match between OpenLiteSpeed, Nginx Stable/Mainline and Lighttpd. All four of these finished their tests within 12 seconds of each other, very close indeed. Nginx Mainline finished first in 4:16, Nginx Stable was second at 4:21, OpenLiteSpeed was third at 4:26 and Lighttpd was fourth at 4:28.
As we can see with the recent changes to OpenLiteSpeed it has definitely been optimized for this type of workload as it’s performing quite close to Nginx, the speeds basically doubled after this. Additionally it looks like Lighttpd is now beating Cherokee more consistently than when I previously ran these tests. The latest version of Varnish cache also noticeably performs better based on the more CPU cores it has available as it moves up in each test, from almost second worst at 1 CPU core to second best at 8 CPU cores.
In my original tests I had some strange performance issues with Nginx only using around 50% CPU at the 4 and 8 CPU core counts, after being contacted by Valentin Bartenev from Nginx and provided with some configuration change suggestions Nginx seems to be performing much better as can be seen by it coming out first in every test here. I think most of the performance increase was a result of removing “sendfile on;” from my configuration as suggested, as this is not much use for small content, and as mentioned I am using a 7 byte HTML file. Other suggested changes which helped improve performance included these:
accept_mutex off; open_file_cache max=100; etag off; listen 80 deferred reuseport fastopen=512; #I only found this worked in Mainline.
Otherwise the Nginx configuration was default.
Memory Usage
At the end of each test just before the benchmark completed, I recorded the amount of memory in use with the ‘free -m’ command. I have also noted the amount of memory in use by just the operating system after a fresh reboot so that we can compare what the web servers are actually using. The results are displayed in the graph below, and the raw memory data can be found in this text file.
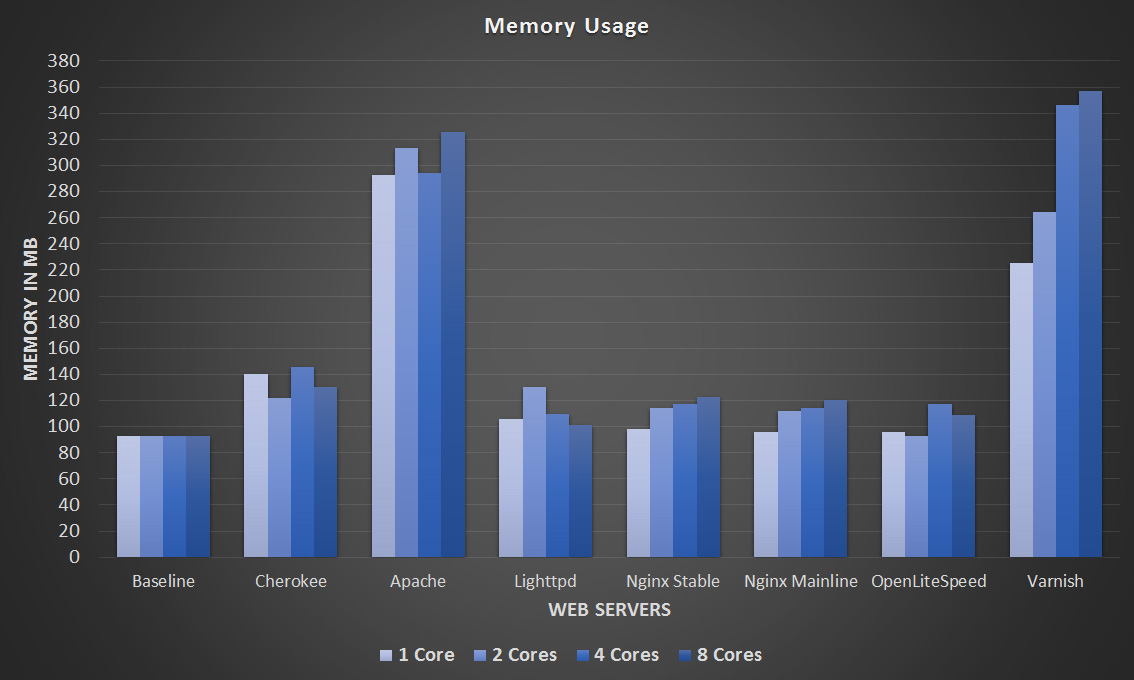
Memory Usage – Click Image To Expand
As you should be able to see, the memory usage was not very much considering the VM had 4gb assigned. This should be expected with such a small and static workload. Despite this Apache and Varnish did seem to use significantly more memory than the other web servers. Varnish is configured to explicitly use RAM for cache, however the static index.html file was only 7 bytes in size. Other than those two, the others are fairly even in comparison.
Total Time Taken
This final graph simply displays how long the tests took to complete in the format of hours:minutes:seconds. Keep in mind as mentioned previously each test will result in approximately 30,000,000 GET requests for the index.html page.
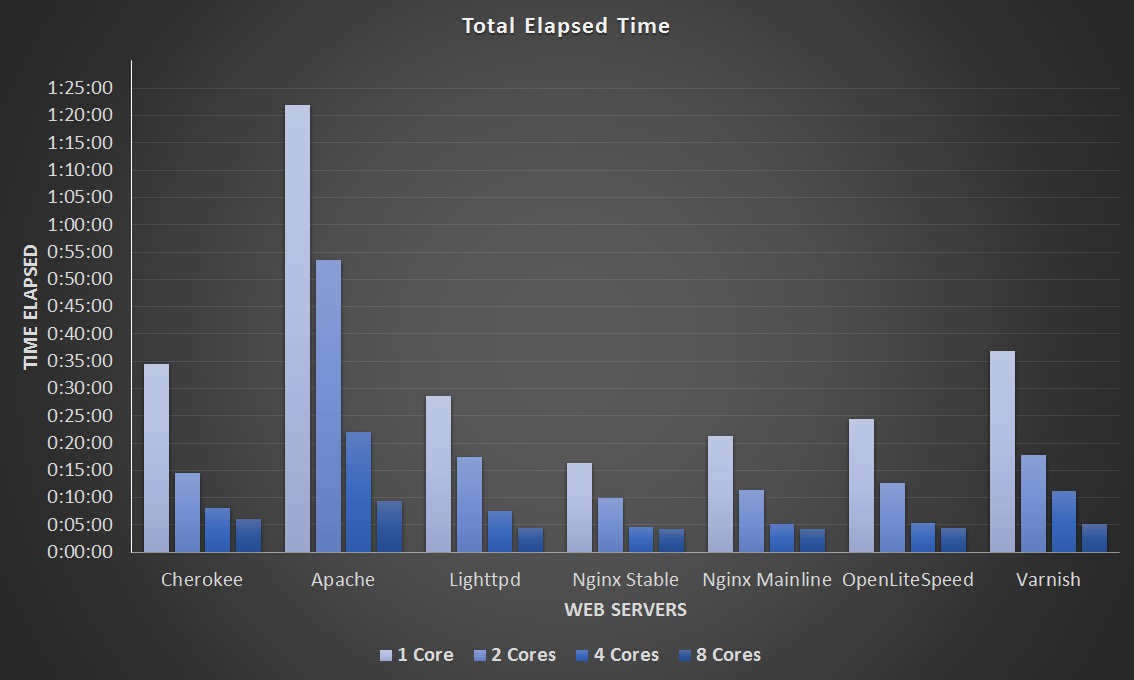
Total Time Taken – Click Image To Expand
The raw data from this graph can be viewed here.
Here we can see more easily that some web servers appear to scale better than others. Take Apache for example, with 1 CPU core the average requests per second were 7,500, double the available CPU and the requests per second double to around 15,000, double the CPU again to 4 CPU cores and the requests double again as well to 30,000, double again to 8 CPU cores and we’re now at 60,000 requests per second.
Although performing the worst overall, the Apache results are actually quite predictable and scalable. Compare this to the 4 and 8 CPU core result of Cherokee, where it seems that very little time was actually saved when increasing from 4 to 8 cores. Nginx on the other hand had very similar results in my 4 and 8 core testing in terms of the total time taken, despite performing the quickest I found this interesting that at this level the additional cores didn’t help very much, further tweaking may be required to get better performance here.
Summary
The results show that in most instances, simply increasing the CPU and tweaking the configuration a little provides a scalable performance increase under a static workload.
This will likely change as more than 8 CPU cores are added. I did start to see small diminishing returns when comparing the differences between going from 1 to 2 CPU cores against the jump from 4 to 8 CPU cores. More cores aren’t always going to be better unless there are optimizations in place to actually make use of more resources.
While Apache may be the most widely used web server it’s interesting that it’s still coming last in most tests, yet using more resources. I’m going to have to look into Lighttpd/OpenLiteSpeed more as they have both given some interesting results here and I haven’t used them much previously, particularly with a higher CPU core count. While Nginx did win I have a bit of experience with this and have used it in the past – it’s the web server I’m using to serve this website.
I’d be interested in hearing if this information will change the web server that you use. Which web server do you typically use and why?
Very interesting. I maintain a web hosting control panel product and I’m busy updating the installer script for Centos 7 (currently it requires Centos 6).
Given these results I will probably use (or at least give the user the option) of nginx. I’ll certainly look into lighttpd too.
Great job, thanks.
Cheers! I’m using Nginx on the web server for this website and it’s been going great for me! :)
Thanks for posting this!
I was wondering if you used default configuration for each of the web servers. Specifically, nginx writes access logs by default, which may impact performance due to disk IO.
No problem, I mentioned in the post that I disabled access logging to prevent disk IO being a limiting factor. Yes a default configuration was used unless official documentation recommended making changes to go along with the increase of CPU cores, in which case those changes were taken such as increasing threads. Other than those small tweaks nothing else changed.
Thanks for the quick reply. I somehow missed that you did mention it… any guess what the impact would be? I assume it depends on the type of disk and the buffer size used.
In a couple of tests I forgot to disable logging, once the disk filled up completely with logs (only 20gb disks) some web servers started performing extremely poorly so it was obvious that it was causing a performance problem. After stopping the test and disabling logging I found that the results prior to the disk filling up were the same as far as I could tell with no noticeable performance difference, this was with SSD backed storage however so maybe it could be more of a problem and there would be CPU waiting on IO with mechanical disk storage.
Awesome. Thanks again!
Hi, could you please put the configuration files for nginx and openlitespeed here? I want to do a further comparison between these two to make a decision to see which one I would choose.
Thanks.
Hi, I want to ask, is gzip function on or off during the benchmark test?
As mentioned default configuration was used, so gzip was enabled by default.
Thanks for confirmation !
Thanks for such test. We actually found a bug related to openlitespeed and now it has been fixed. Openlitespeed is running 2X ~ 3X faster than the one with bug. If you like, you may want to download the source and run another round of test. The game may totally change with such big performance improvement comparing with other web servers.
Once the new packages are available through the official mirror I’ll look at running it again to see if there are any differences.
The new package openlitespeed 1.4.16 is already on LiteSpeed web site and ready for download at any time.
We also did our own test against nginx. Openlitespeed outperforms Nginx. http://blog.litespeedtech.com/2016/03/31/of-benchmarks-and-bug-fixes/
Thanks, I checked the repository again and it looks like the new version came out on the 29th of March. I’ve updated now and I’m testing again, so far it does look to be significantly better!
I’ve updated the graphs based on the patch and it looks like OpenLiteSpeed comes out on top in all tests for this particular workload now!
Can you add g-wan server as well into ecuation ?
I had a lot of difficulties getting it working, it kept crashing part way through the test so I left it out this time, however from the results that I did get it is still extremely fast.
Hello Jarrod. The default nginx configuration isn’t optimized for such synthetic benchmarks. If you send me an email, I will suggest you directives to tune.
Thanks, I’ve put in place some of your suggestions and have found they help at the lower CPU core count more than at the higher core count. I am getting perhaps 50% improvement in some tests simply with default configuration with mainline 1.9.13 which came out not too long ago, so I am thinking that something may have been fixed or improved over the original 1.9.12 I tested with that has resolved the problem I was having. With that said with the 4/8 CPU core tests I still see quite a bit of CPU resources free, however the requests per second are definitely a lot higher. I’ll update my results once I have some time to complete my full testing.
You should also check what happens with your client. Given your testing environment setup, my experience with weighttpd, and what happens with results after only 600 concurrent connections, I tend to think that you are mostly benchmarking weighttpd and VM setup, not the webservers.
Try, for example, wrk and look if it give you different numbers: https://github.com/wg/wrk
The client has plenty of resources available, I can’t see any sort of bottleneck there when I run the test. Weighttpd is definitely capable of pushing a lot more requests as I’ve seen it go much higher with different web servers before. I’ll take a look at wrk when I get some time, thanks.
Your results are very low. Here is what I can get on my a way less powerful (Core i7-4770S) desktop locally:
$ wrk/wrk -t4 -c1024 http://127.0.0.1:8080/7bytes.html -d1m
Running 1m test @ http://127.0.0.1:8080/7bytes.html
4 threads and 1024 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 13.19ms 65.78ms 872.12ms 96.87%
Req/Sec 88.57k 10.44k 125.20k 95.97%
20552841 requests in 1.00m, 4.61GB read
Requests/sec: 342136.94
Transfer/sec: 78.63MB
this is for a 7 bytes file similar to your tests:
$ curl -i http://127.0.0.1:8080/7bytes.htmlHTTP/1.1 200 OK
Server: nginx/1.9.14
Date: Thu, 07 Apr 2016 19:27:45 GMT
Content-Type: text/html
Content-Length: 7
Last-Modified: Thu, 07 Apr 2016 18:38:25 GMT
Connection: keep-alive
ETag: "5706a921-7"
Accept-Ranges: bytes
7777777
with a very simple config:
worker_processes 4;events {
accept_mutex off;
}
http {
open_file_cache max=16;
server {
listen 8080 deferred;
keepalive_requests 1024;
location / {}
}
}
I’m not so sure about the i7-4770S being less powerful, your desktop CPU is rated almost double the score in single thread performance on Passmark compared to the CPU I used in my testing: http://www.cpubenchmark.net/compare.php?cmp%5B%5D=1884&cmp%5B%5D=1983
I’ve redone all of my tests with the mainline version of Nginx and it is now performing fastest at all different core levels, I just haven’t had time to update the graphs yet – hopefully I’ll have time this weekend to update the post with the results. I also want to try wrk to see if if there’s much difference between benchmarking tools.
The post has now been edited to include the updated test results, Nginx Stable/Mainline are in first and second place now! Thanks for your help.
I run nginx on my community website.
It is soo powerful, lately with with dos attacks specific to apache. I love it when they hit my server and it just shrugs it off :P
Cool :) yeah I definitely prefer it over Apache a lot myself. I started out with Apache many years ago as most of us probably did but there are definitely better options out there for high performance.
Open LiteSpeed released a new version with further optimization and make it even faster. We noticed recent tuning from Nginx may be only good for this special test case, but not likely to be used in a production environment, for example: “sendfile was turned off”, “etag header was turned off”. We did not make such special tuning and leave the configuration as default,closed to production environment, but only make optimization effort on code side.
Now the result is: openlitespeed default (production) configuration without special runing is faster than Nginx special running for this case through our internal benchmark test.
http://blog.litespeedtech.com/2016/05/03/openlitespeed-does-it-again-1-4-17-retakes-the-lead-in-serving-small-static-files-with-its-default-configuration/
New release is out there for download. Feel free to try and test it out.
Interesting! I’ll check it out when I get a chance, thanks for letting me know.
Hi Jarrod,
have you take a look at https://caddyserver.com/ ?
Not yet, it looks interesting for static workloads such as the ones I’m testing here so I’ll look further if I get some time, thanks.
Never enable tcp_tw_recycle on a production server! We had a sliver of clients experience intermittent connectivity issues without anything in the server logs. Recycling was to blame.
See also:
https://vincent.bernat.im/en/blog/2014-tcp-time-wait-state-linux.html
Thanks for the information, that’s interesting.
Agree with Tark on this one, enabling fast recycling of TIME_WAIT sockets is usually a bad idea as it will cause you a lot of problems when working with NAT.
Thanks for sharing your test results.
I am curious if you might consider testing Apache’s “Traffic Server” in a configuration similar to Varnish.
Of immediate interest to me is the impact of SSL on each of these servers.
It sounds interesting, I may try in the future!
Why haven’t you included Apache with MPM-event or MPM-worker?
While I can’t recall exactly, I think I changed tp the MPM Event for a test and got basically the same results so didn’t bother with it. Compared to the rest it didn’t change that much, it might be worth investigating further in it’s own post however to compare the different options Apache has.
Great job! Thank you for the performance benchmark. It would be better if you can have another comparison benchmark for serving dynamic contents. I think it could be much helpful since nowadays many sites have CDN in the front and static contents usually won’t be an issue.
Thanks, it’s definitely something I want to look into!
Can you explain why the same number of requests per second occur with 100 user and 1000 users? I would expect the request load to be 10X in a healthy test environment?
Good web servers are able to scale well like this even with higher number of requests. Additionally the test here is only a static page so additional requests aren’t that expensive, compared to if I was testing something with dynamic content like a PHP page.
You didn’t understand my question.
If one user generates one hit, then 100 users generate 100 hits and 1000 users generate 1000 hits. Same for connections, etc.
Your test environment is not working properly. You can see in the graphs that the scale is constant regardless of the load. Usually, this means you have a bottleneck in the environment. It could be a network than cannot handle the traffic, or that your load injector is overwhelmed and cannot handle the responses coming back from the server.
Try running the test at lower levels and you will see that the req/s and connections graphs are directly proportionate and scale with the load. When that stops happening, you’ve got a problem. It’s obvious that it happens before 100 users if you look at the graphs.
(Mercury LoadRunner certified consultant- we invented load testing software)
Thanks for this benchmark!
If possible it would be interesting to also add some HTTP/2 web servers like Caddy and ShimmerCat for testing?
Most of these do support HTTP/2 now so it’s something I’ll look at including in a future test.
Hey Jarrod
nice benchmark I’m just wondering how https://h2o.examp1e.net/ this stacks up at all or even if it is competition
I’ve been trying to run It myself but I’m rather new to the whole thing and have been having trouble setting up in ubuntu.
any chance on seeing a comparison or mayb a tutorial on how to set it up if its any good?
Hey, I’ve installed it on the same server that I originally ran these tests on, and surprisingly in almost all cases it came out first. Interestingly at 4/8 CPU cores it was pretty close to Nginx, however I noticed that there was still lots of CPU power available so perhaps it’s not as scalable there. At lower core counts such as 1/2 it definitely wins by a significant margin, which I suppose shouldn’t be much of a surprise if this has been specifically designed to serve static files.
In any case I’ve uploaded the results below, I’ve included h2o in with the previous graphs for comparison.
1 CPU Core: https://www.rootusers.com/wp-content/uploads/2016/10/h2o-1-core.png
2 CPU Cores: https://www.rootusers.com/wp-content/uploads/2016/10/h2o-2-core.png
4 CPU Cores: https://www.rootusers.com/wp-content/uploads/2016/10/h2o-4-core.png
8 CPU Cores: https://www.rootusers.com/wp-content/uploads/2016/10/h2o-8-core.png
Total Time: https://www.rootusers.com/wp-content/uploads/2016/10/h2o-total-time.png
Regarding setting up in Ubuntu, it doesn’t appear that there are files for that supplied. I’m using CentOS so it was simply a matter of installing the RPM. They note that you should open a new issue on Github requesting packages for any other operating systems, so perhaps you could do that and ask for Ubuntu/Debian. Otherwise you could try installing from source: https://github.com/h2o/h2o/
Thanks for the update Jarrod! H2o looks really promising.
Hello, can you please try Mighty (Mighttpd2/Warp) on your test machine? People say its as good as nginx, but it would be nice if you could test it too.
I’m interested, but I haven’t been able to get it setup on CentOS 7 yet based on the installation documentation. I’m getting a bunch of dependency issues with aeson on a clean build.
The Haskell compiler (GHC) in the EPEL repo seems to be too old. I tried a few things in a CentOS VM, but I couldn’t get Mighty compiled either.
I could try another distribution, but I wouldn’t consider the results exactly comparable to the others in my test as this is at least some small difference, I’ll see what I can do.
I compiled Mighty on my Fedora with GHC 7.8.4 (newest version in Fedora repo). Its not the nicest solution, but I could copy the binary to my CentOS VM and it worked.
Uploaded binary here: http://naivelabs.org/pub/mighty.tar.gz
Thanks, I’ll see if I can give it a go when I return from holiday.
Id like to see something like Jetty (Java) benchmarked in this. I’m currently testing web-app frameworks in various languages to try to get my own numbers but the more people, the more data, the better decisions (at least greater probability of better decisions).
Thank you for this great test. But im wondering the comment of Steven
https://www.rootusers.com/linux-web-server-performance-benchmark-2016-results/#comment-2381
in this case, when 100 connections makes 30000 requests, why 1000 cconnections still makes 30000 requests?
Could you maybe try Lwan (https://lwan.ws) next?
Sure I’ll try include it in my 2017 test post.
many thanks for this benchmark, I was looking for a good comparison, and I found it here :)
Can you share your Varnish coniguration and VCL?
Unfortunately I can’t as I don’t have the VM that I ran the test in any longer. The configuration was very stock standard though, I didn’t change much at all. The main thing I did was ensure the cache was set to use memory rather than disk and that was mostly it.
By default, Varnish will request a gzipped response (from nginx), store in cache gzipped, and then ungzip on delivery if the client doesn’t support it. Most benchmarking software does not Accept-Encoding gzip, meaning Varnish un-gzips each and every response. Make sure to explicitly disable this functionality, if you didnt in your original benchmarks. Otherwise Varnish is likely doing a whole lot of work that the other servers aren’t doing.
It’s a fair point, however I can see that I noted gzip was enabled for other web servers too, though of course as mentioned I don’t have the VM so can’t confirm this, I’ll confirm it and note it explicitly with future benchmarks, thanks.
Sure you should try with Apache mpm event or worker !
Testing all those novelty servers is hardly useful for most people, and at the same time there’s no test of all of the various Apache MPMs that a lot of people have encountered ‘in the wild’: worker, event, ITK…
Examine the popcon (package popularity contest) of Ubuntu and Debian to determine which web servers are actually relevant.
Also, a payload of more than 7 bytes would be much more useful, because that’s a very artificial type of a request.
As mentioned in the comments I’ve tested various Apache MPMs, the problem was that the difference was so insignificant when compared against other web servers that I didn’t bother including them. I’m considering instead doing a future post where I only look at the different options available in Apache.
It should also be noted that the TCP window size changes (tcp_mem, tcp_rmem, tcp_wmem being in the range of 30 MB) are settings that can do nothing to improve 7-byte request performance, not even with a lot of header overhead, because each TCP connection will never reach the segment sizes necessary for the window to be stretched that much. It’s become rather common to see online examples of ‘high-performance tuning’ which doesn’t actually make much sense.
Good to know.
Jarrod, your sysctls are completely bogus I’m sorry :
– tcp_mem counts in pages, not bytes so you allocated 114 GB of RAM to the TCP stack
– somaxconn is 16 bits so 100000 doesn’t fit, is rejected and either the default 128 stays (recent kernels) or only the lowest 16 bits are used (34k)
– tcp_rmem and tcp_wmem default values cause the system to try to allocate 30MB for the read and write buffer upon each accept/connect, that results in disastrous perfs.
– tcp_tw_recycle must NEVER be set (never ever) otherwise you’ll randomly see some fantom sockets closed on your client but still established on the server, causing jerky traffic spikes.
– the other ones are clearly random values padded with zeroes
Also it’s not mentionned whether or not you properly stopped iptables and unloaded conntrack modules (nor if you left it without tuning it). You cannot claim to correctly compare products with such settings, these bogus settings add a huge amount of randomness in your measures. I’m not surprized Valentin got much better values. The problem is that some people with copy-paste your settings for their production servers and report issues to the product vendors.
That’s possible, I didn’t create them after all. I believe I used the same settings defined here: http://gwan.com/en_apachebench_httperf.html
This was because I came across G-WAN initially which is what peaked my interest in performing my own tests.
To be honest I can’t remember the specifics like iptables as this was over a year ago, however it would have been the same on all tests, and as long as that is the case then I believe the comparison between them all is still valid in this aspect.
Additionally I advise not using these settings in production in the post and state that they were only modified for benchmark purposes.
I’m more than happy to take advice from an obvious professional in this area such as yourself before I perform future testing, feel free to advise me on all correct settings that I should use.
Wow, gwan being a server vendor they have zero excuse for doing these huge mistakes, and you’re easily forgiven! I thought they were doing serious stuff now I have the proof that they don’t know what they’re talking about when it comes to performance, which they claim is their main differenciator…
iptables (in fact conntrack) can show very different behaviours depending on how connections are closed, how long they last, etc, so it can in fact inflict different behaviours to different products. And when the conntrack table is too small, the performance is quite irregular along time. The hash_buckets significantly affect session lookup time, which is a problem after you have hundreds of thousands of time_wait entries left. That’s why it’s much better to unload it during such tests.
Your tcp_rmem and tcp_wmem settingss shouldn’t be changed, or at least you should only multiply the 2nd and 3rd numbers by two but even then you won’t notice any difference. tcp_mem requires values in number of pages (4096 bytes). With a webserver a reasonable default setting (middle number) is 1/3 to 1/2 of the RAM. The first and 3rd values (min and max) can be set to the same value, or set to close values like 3/4 and 5/4 of the default one.
tcp_tw_reuse is properly set, but tcp_tw_recycle must always remain zero. Be sure to enable tcp_sack when testing large objects as it avoids retransmitting large parts of the window in case of losses.
somaxconn and tcp_max_syn_backlog are both 16-bit so they should be below 65535, and normally not too large otherwise in production you can’t get SYN cookies during a SYN flood. Values between 1k and 10k are reasonable for production and benchmark, anything below 1k for any of them can be a bit short and anything above 10k is often useless.
You don’t need to change optmem_max, core.rmem*, core.wmem* as they’re used for non-tcp protocols and for ancillary data when doing sendmsg(). You can have to significantly increase tcp_max_orphans when not using http keep-alive (typically the same number as max_tw_buckets, but be careful about the memory usage due to the large tcp_wmem).
You may want to tune a bit tcp_limit_output_bytes with certain NICs if you can’t fill the link with large objects. Sometimes reducing tcp_min_tso_segs to 2 increases the performance on medium-sized requests (<3kB) but it depends a lot on the NICs and drivers and can have the opposite effect. For benchmarks on the local network you can often set tcp_no_metrics_save which will save you a bit of CPU by not updating the TCP metrics for each connection, but in production it's not recommended.
Last point, benchmarks in VMs suffer from a lot of randomness, so you absolutely need to ensure that you assign full CPUs to your VMs and that no other VM is running on the same hypervisor.
Thanks for the information, I think next time I might just stick to the defaults in CentOS rather than making any modifications, do you think that will be fine? At least then it would more accuratley represent what most people would be getting as I assume those are tuned for general purpose workloads and it would be good to provide something more reproducible to everyone. In this case the hypervisor was only running my two test VM’s so I think that was alright. I’m looking at running the tests again sometime this year for a 2017 follow up so will consider this as well as other feedback I’ve had when performing those tests.
Yes, running with centos defaults should be relatively fine and as you said it will reflect what end users should expect. At least unload conntrack if it’s loaded and set tcp_tw_reuse as I’m not sure it’s set by default. If you get very different or irregular performance, try to change only somaxconn, then tcp_max_syn_backlog.
As Willy already pointed out, there were many errors induced here.
If conntrack cannot be disabled or unloaded, make sure you’re doing NOTRACK in the raw table:
iptables -t raw -I PREROUTING -j NOTRACK
iptables -t raw -I OUTPUT -j NOTRACK
It would be interesting see a comparison with freebsd latest version with the same web servers running the same tests.
I’ll keep that in mind for future tests, thanks!
Hello, i want ask about optimize nginx and cache.
How to calculator which number i need ? like worker_connections and buffer ?
And Redis, Memcache which one better ?
I recently came across “Hiawatha webserver” which comes with some very nice security features built-in by default. It also claims to remain performant whilst under attack. As another lightweight webserver option, it sounds like an excellent candidate to include in your testing, perhaps? Certainly I’d be interested to learn how it stacks up in use.
If I do the testing again I’ll go through the comments and use all the suggestions, so you may see this in future :)
Great Work!! Well done.
I
What about error rates in case of 1000 users in 1 core cpu. Are you able to serve all users successfully?
Another question, when you assign 1 core cpu, is the cpu workload stays constant under different number of concurrent users scenarios (100-1000 users)?
If I recall it stayed somewhat constant after building up for a little. With Apache the load seemingly continued to grow continually. I didn’t note any errors from the test, that is any non 200 responses.
you made a point here and thank you, my next project is to install Nginx!
only issues I see is how to convert the htaccess files…
Yeah I had a bit of work to do when I moved from Apache to Nginx for this site a few years ago, it’s been smooth sailing since I got the equivalent rules working in the Nginx config :)
Not everyone heard of H2O HTTP Server which is more stable and performant than Nginx based on a contributior slideshare, i110.
H2O in C also appear on TechEmpower benchmark is quite good although you seen Actix-raw in Round 16 in fact is a stripped test, not a proper one.
It would be interesting see a comparison with freebsd latest version with the same web servers running the same tests.
Not much accurate test. OpenLiteSpeed dominate all. And yes, its only free version…
I have Eshops with 120,000 products and daily update XML with prices. Nginx with Apache die in minutes, OLS after hours no problem…
I await for you to create a better test then, Thomas. Let me know when you’ve got some data I can take a look at.
No doubt things have changed in the *checks notes* 8+ years since I made this post.